Project Approach
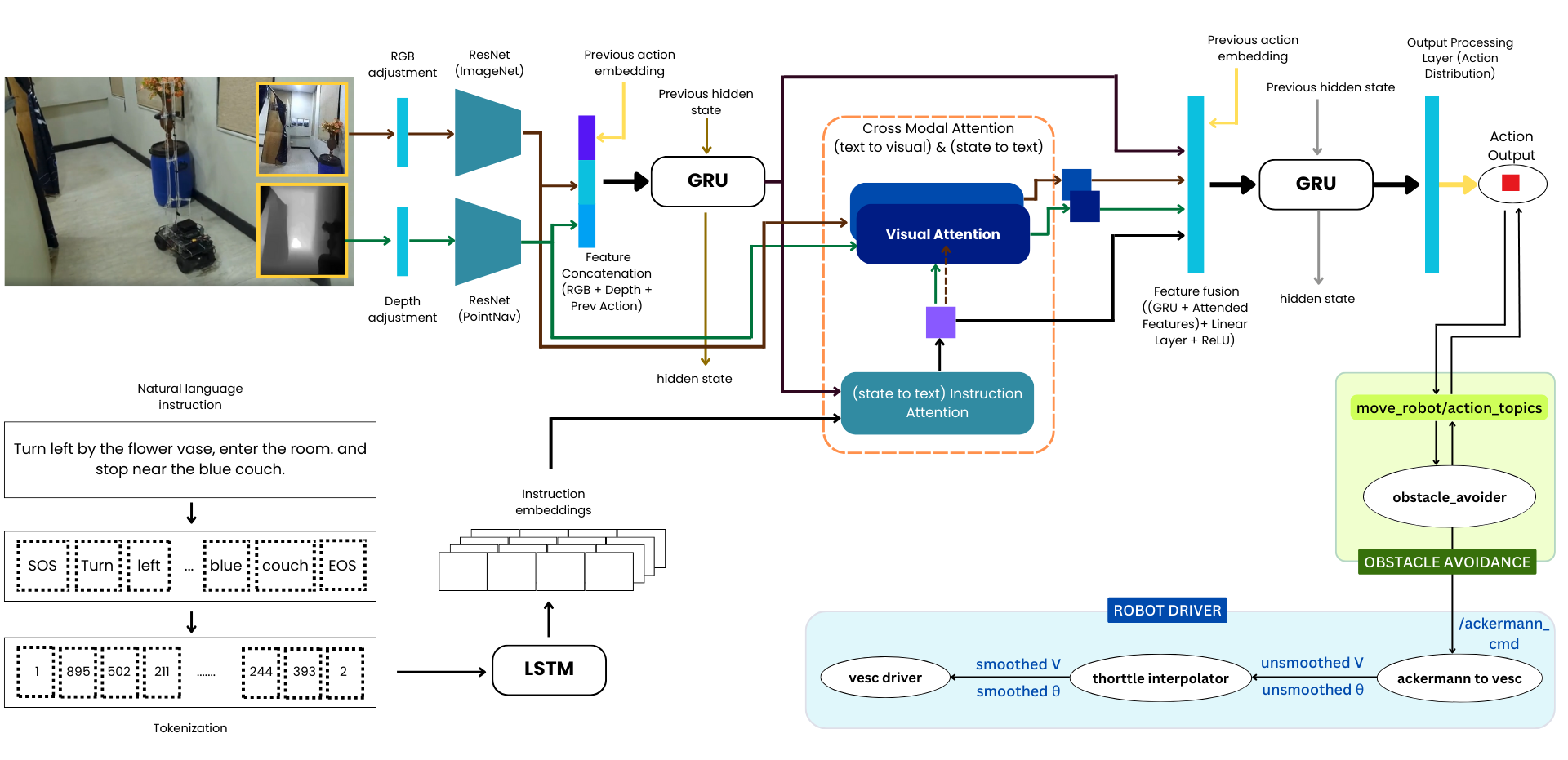
System Architecture
Experiments

Chalindu Abeywansa, Sahan Gunasekara, Devindi De Silva, Seniru Dissanayake
Ranga Rodrigo, Peshala Jayasekara
Vision-Language Navigation (VLN) enables robots to navigate through environments using natural language instructions, making human-robot interaction intuitive. Traditional VLN models often rely on navigation graphs, 360-degree views, and perfect localization which pose significant challenges when adapting these models to real-world settings. This work addresses these limitations by performing a simulation-to-real domain shift of a VLN approach that operates in continuous environments without requiring navigation graphs or panoramic views. The proposed system integrates vision-language models that align visual inputs and linguistic instructions within a shared embedding space, facilitating natural language-driven navigation. We employ a Cross-Modal Attention (CMA) based architecture trained on an existing dataset in a simulated environment and fine-tune it using real-world data collected from a custom-built Ackermann-steered robot equipped with a camera and a LiDAR sensor. By utilising linear photometric adjustments and fine-tuning on a limited number of episodes, our model successfully adapts to real-world environments, achieving effective navigation while running offline on dedicated hardware. Experimental results, evaluated using Success weighted by Path Length (SPL) and Normalized Dynamic Time Warping (nDTW) metrics, demonstrate the robustness and adaptability of our approach.
